
Scraping ASP-based dashboards at the protocol level
How to replace Selenium and browser automation with HTTP exchanges
We’re generally lucky, as journalists, to live in a time when open data portals and releases have become common reporting tools. However, “generally” is not “always,” and there are still plenty of times where “open” data has to be more forcibly extracted from a web-based dashboard. Here at Chalkbeat, we write our fair share of scrapers, depending on the bureau and the local public records regime.
Scraping is not a crime, and I’ve got the t-shirt to prove it. But just because it’s legal doesn’t mean it’s easy, or that the administrators of data sites make programmatic access a priority. Even if they’re not intentionally obfuscating data, the tools that are used for government data release were often designed in ways that make extraction difficult.
Sites using Microsoft’s ASP framework are particularly notorious for being opaque to simple scraping techniques. Faced with one of these dashboards, many data journalists turn to browser automation tools, like Selenium, that let them script clicks and keystrokes. However, this approach brings its own challenges:
- Our fleshy, human eyes can easily see when the page is “interactable,” but it can be difficult to tell a computer when a page is ready to receive clicks, meaning that the script will either try to click/type too quickly or incorporate error-prone delays.
- Pages are often not designed to be used programmatically, so we have to figure out selectors for inputs that may not be marked clearly, or might not exist until JavaScript creates them.
- A browser will try to load images and other resources, many of which we don’t “need” for the data and which slow down our process.
- Selenium requires a lot of memory and isn’t tremendously stable, which often means it’s tough to run on an EC2 instance or another virtual machine for automatic scraping at regular intervals.
As an alternative, instead of pretending to be a user with a keyboard and mouse, we should pretend to be a browser client that only knows how to send and receive messages. Essentially, we will drop down to the actual HTTP exchange layer.
Scraping via pure requests is more abstract and requires us to understand a bit more about the client/server protocol, but it reduces the process to a simple set of back-and-forth transactions: we send a message, record the response, rinse and repeat.
Ironically, the “smarter” and more interactive a page is in terms of client-side code, the more likely that it’s backed by simple HTTP endpoints that the scripts (and in many cases, native apps) are talking to, and which we can also contact for data directly.
In contrast, ASP dashboards are difficult not because the underlying software is sophisticated, but because it was designed and implemented before developers standardized around a more expressive use of these APIs.
Understanding HTTP
MDN has a reasonably good guide to the HTTP protocol if you’re interested in the details, but for our purposes we can think of it as a simple call and response. Every time you load a page, the browser sends a request to the server, and receives a response in return. This may trigger additional requests (e.g., a page may contain images, scripts, or stylesheets that the browser needs to download).
An HTTP request can be broken down into a few parts:
- The URL path being requested from the server
- A method “verb” expressing the action for the request, most commonly GET or POST.
- Headers that add metadata to the message, including cookies and the preferred language.
- An optional body section that can contain data being sent to the server.
Most of the time, in a browser, there’s no body and the request method will be GET, since we’re just asking to download a file. POST requests are used to upload to the server or make changes, and usually do include a body with the data that the user wants to submit (such as a file upload or the contents of a form).
Here’s a typical request made to Chalkbeat, for example. You can see the method, path, and headers. As noted, since it’s a GET, there’s no message body after the headers.
GET https://www.chalkbeat.org/ HTTP/1.1
Host: www.chalkbeat.org
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:105.0) Gecko/20100101 Firefox/105.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
DNT: 1
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: cross-site
The server processes the request and sends back a response that’s structured in a similar way. Responses don’t have a path or method, but they include a numerical status code indicating success or failure (such as 200 OK or the infamous 404 NOT FOUND). They also have headers for things like modification date, and they almost always include a body section containing the data we asked for in our request.
Here’s the raw server response to our request, trimmed for length:
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Connection: keep-alive
Date: Mon, 24 Oct 2022 14:28:23 GMT
Server: istio-envoy
strict-transport-security: max-age=31536000; includeSubdomains;
x-powered-by: Brightspot
x-envoy-upstream-service-time: 983
x-envoy-decorator-operation: brightspot-cms-verify.chalkbeat.svc.cluster.local:80/*
Vary: Accept-Encoding
X-Cache: Hit from cloudfront
Via: 1.1 b75f3304a39fe185ba1556322bdff970.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: ORD58-P2
X-Amz-Cf-Id: yvRz34BFe8NslGGux897su17I-QKBj-XRFGDCNj23Bjx8-pmqkaUlw==
Age: 45
Content-Length: 414837
<!DOCTYPE html>
<html class="Page" lang="en" data-sticky-header
>
<head>
(... body continues with the rest of the HTML)
We don’t typically look at raw HTTP requests (I had to install a proxy in order to do so). However, if you open up the dev tools and look at the network tab, you can see all of these in your browser in a more readable form:
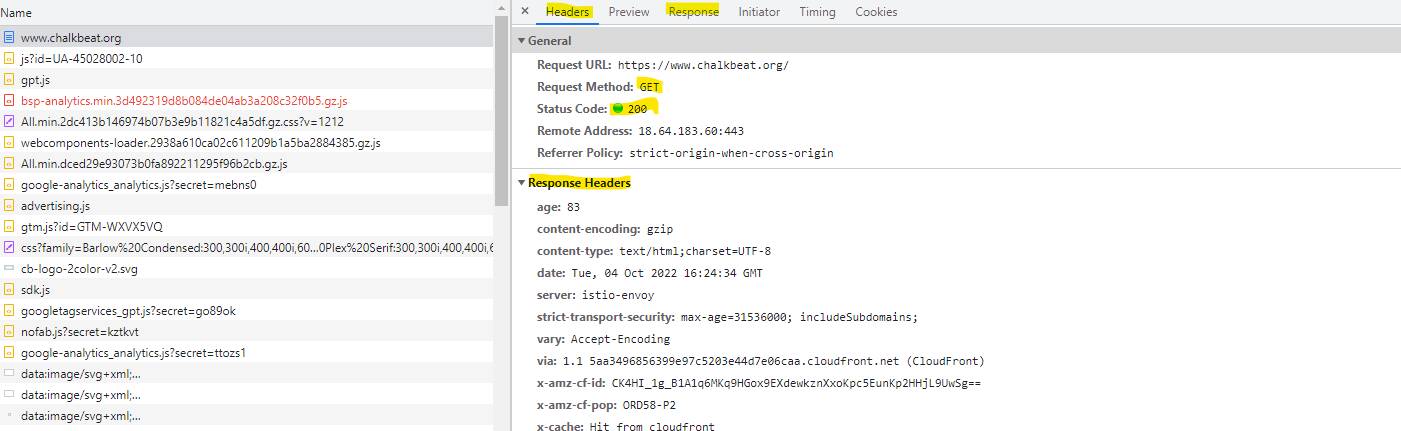 “Headers” will show you the request method, response status code, and the headers that were sent by the browser and back by the server. Click “Response” to see the message body.
“Headers” will show you the request method, response status code, and the headers that were sent by the browser and back by the server. Click “Response” to see the message body.
When scraping a website, although it’s tempting to look at the DOM inspector, it’s often easier to just go straight to the network tab and see what messages are being sent when interacting with the page (especially with the filter set to “Fetch/XHR”, which will only show requests made by client-side JavaScript). To me, this is similar to asking for machine-readable data in a FOIA instead of trying to OCR a document scan – the latter is possible, but it’s usually a lot more trouble.
How a normal site uses HTTP
A typical web application does almost all its interactions using the GET method (meaning, the browser wants to read data but doesn’t want to write it) and differentiates between views using the URL. As a refresher, here’s the parts of a URL (image courtesy of MDN):

Different data views are usually expressed using either the path or query parameters. Either way, you have a specific URL that you can construct and request in order to scrape data out of the service. Since you’re not changing anything, you can just use GET instead of one of the other HTTP verbs, and you don’t have to send a request body to the server. This pattern – where a resource is made available at a given address regardless of other requests that have been made – is often referred to as RESTful. It’s popular because it’s also easy to implement, and friendly to caching (meaning that it’s cheap).
How ASP pages use HTTP
The first thing you will notice when trying to scrape an ASP-based site is that you’ll see repeated requests made to the server for different data, but all using the same URL. In order to extract data from these, we have to learn to send our requests in a slightly different format.
For example, let’s load the NYC school-based expenditure report dashboard, then select District 1 to look at. The page will refresh, and the document request will look like this:
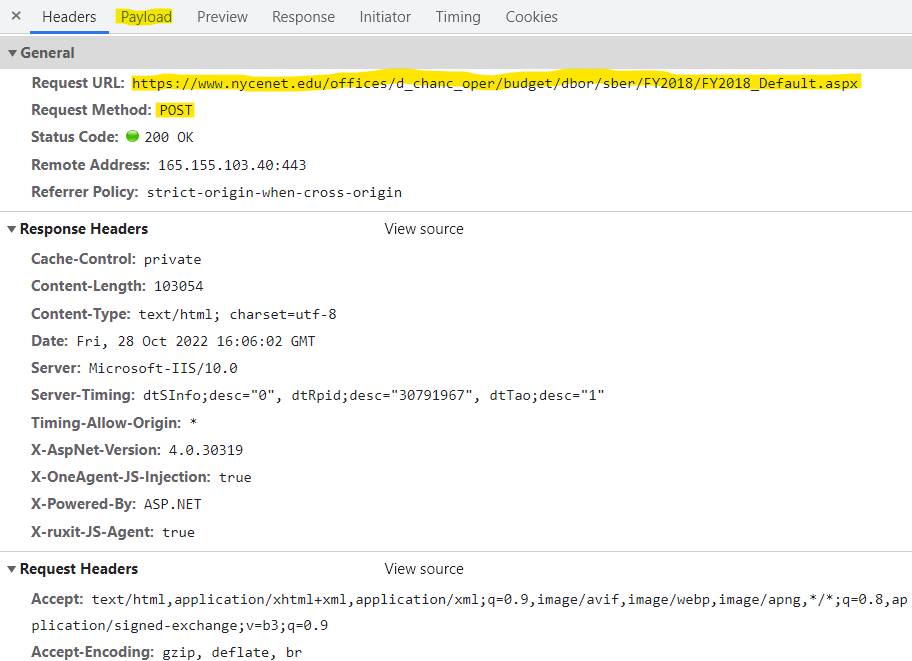
The request URL is the same as the page we’re on, but notice that the method is a POST, not a GET. That usually means that we’re sending data to the server in the request body.
We can see what we sent by clicking over to the Payload tab:
 (many lines of _VIEWSTATE later…)
(many lines of _VIEWSTATE later…)
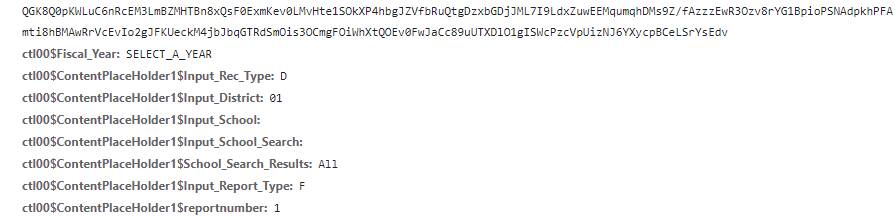
When we changed the drop-down to select the district, instead of simply requesting data from a new URL, the page actually made a form submission with a number of parameters corresponding to the dashboard settings and a unique value assigned to our viewing session (the _VIEWSTATE). If you inspect the page, you can actually find the hidden form inputs that it uses to generate this:

What this boils down to is that ASP pages are not inherently stateless the way that most HTTP endpoints are. Instead, the server is maintaining a session for you and each transaction has to match that session. You can imagine this as though the dashboard has its own browser tab open, identical to yours visually, and when you click a button, the page tells the server to perform the actual click in its tab, and then it sends the updated page back to you. If you try to make a request that doesn’t match the server’s idea of where you “are” on the site, it’ll usually just send the index page back to you as a fallback.
Luckily, even though this is a dizzyingly overcomplicated way to run a server, it’s not terribly hard to send these events from our side. We just need to make our own POST request that includes the values that the server embedded in the form, updated with the correct input parameters. Step-by-step, that process usually looks something like this:
- Get the initial page, and pull out the hidden input values into a state object. We could be more discriminating, but the easiest way to do this for ASP is to just query for inputs with
type="hidden"set on them, and create an object out of theirnameandvalueattributes. - Update the filter values in that object. Usually I find these values by poking around in the network tab and seeing what changes when I update the form – this form input produces that form value in the POST submission.
- POST that object to the server and pull data out of the response.
- (optional) Update our state object to match the response, then repeat from step 2.
You can see an example scraper for a couple of NYC finance pages in this Gist. Of particular note is the getASPValues function, which extracts the hidden form inputs:
async function getASPValues(target) {
var response = await fetch(target);
var html = await response.text();
var $ = cheerio.load(html);
var data = {};
var inputs = $(`input[type="hidden"]`);
for (var i of inputs) {
data[i.attribs.name] = i.attribs.value || "";
}
return data;
}
There are also some values that I snooped from the network tab, such as the _EVENTTARGET (which tells the server that we changed the district drop-down):
const sberFormValues = {
_EVENTTARGET: "ctl00$ContentPlaceHolder1$Input_District",
ctl00$ContentPlaceHolder1$reportnumber: 1,
ctl00$Fiscal_Year: "SELECT_A_YEAR"
};
We can then combine our ASP form values, our event constants, and our specific filter setting into a form submission and POST it to scrape a given district page:
var getSBER = async function(asp, district) {
var data = {
...asp,
...sberFormValues,
ctl00$ContentPlaceHolder1$Input_District: String(district).padStart(2, "0")
};
// generate a form-encoded POST body
var body = formEncode(data);
var response = await fetch(SBER, {
method: "POST",
headers,
body
});
var html = await response.text();
var $ = cheerio.load(html);
var rows = $(".CSD_HS_Detail");
var scraped = [];
for (var row of rows) {
var { children } = row;
var cells = children.map(c => $(c).text());
scraped.push(cells);
}
return scraped;
}
This code is in JavaScript, but the equivalent in Python using BeautifulSoup is pretty straightforward. I recommend using Requests to send your POST, since it will automatically encode the data for you and set the correct header to match the form content type. The above linked Gist also includes a port of the scraper to Python for comparison.
Although it seems complicated compared to typical scraping tasks, once you’ve written a few of these and the building blocks are more familiar, you’ll be able to write ASP scrapers very quickly. And as you become accustomed to working through the network protocol, not the UI level, you’ll be impressed by how much of this same technique can be adapted to other scraping tasks, including script-generated data views and native applications.